大二左右的时候研究过pt,记得主要看的demo是smallpt,一个两百行的c++全局光照demo。当时基础很差,看的很费劲,但大致还是看懂了。我为什么这时候又要重新关心这个东西了呢?因为公司产品的显示效果太差了,怎么才能有质的飞跃秒杀竞品呢?当然是上全局光照啊。。
因为要满足实时性的需求,一般的3d cad类型应用都是使用标准的光栅化管线渲染,无法表现正确的基于物理的光影着色,为了更好的效果,可以使用shadow map和shadow volume可以做出正确的硬投影,可以使用ssao添加全局照明的近似视觉效果,更复杂的效果使用更trick的手段来模拟。但是这些效果往往很不如意。
实时效果做的最好的一般是游戏行业,但是游戏行业的实际场景特点和我们有很大不同,首先游戏中大部分物体,光源,场景是静态的,这部分往往投入海量的美术资源进行人工修饰调优,并预计算预烘焙大量直接投入管线显示的纹理资源,以追求极致的效果。而我们的实际场景是全动态的,没有这样做的可能。另一方面,游戏平台相比于web有完整的先进的图形api支持,webgl的api来自opengl es,相当简陋,还需考虑移动端设备的显示性能,能做的事情非常有限。
所以我的结论是webgl做实时的渲染难以追求极致的效果。既然依然要追求极致的效果,那么只能放弃实时性的要求。这个让我想到的最佳例子是3dmax的真实模式,当视角固定后,显示变得越来越细致,逐渐加入抗锯齿和真实的光影效果。这个效果,或者说这个出效果的方式我认为是图形显示改良的一个很好的参考方向,于是我调研了一些准实时前端全局光照的实现。希望能够应用在产品中,当然,即便发现难度太高,自己做着学习也是极好的。
基本原理
既然是path trace,那么和光栅化管线的一般用法是一点关系都没有,管线的作用仅仅是为了显示结果和加速计算,根本不要有什么把顶点数据喂进去,走着色器出结果的想法。
具体是这样操作的:准备两个纹理A,B,作为画布,和canvas大小一样。分两个阶段:第一步首先运行trace的program,主要负责采样计算并更新颜色,将B纹理传入作为之前的采样历史信息,然后将framebuffer指向A,向A更新新的采样计算结果。第二步,交换AB,使得下一轮trace program拿到的采样信息是新的,然后运行render的program,传入A,将旧的采样结果直接显示在屏幕上。
采样的逻辑在traceprogram片元着色计算中,主要是根据相机位置参数和屏幕采样位置生成光线,然后和场景求交,获取最近交点的坐标和法线。得到交点坐标和法线后,生成以交点为起始点,采样BRDF重要性作为新的方向的新的光线,继续和场景求交,反复这样的path trace 多次,逐个通道累计计算路径上相交点的亮度和吸收率,并相除,经过曝光除法和伽马矫正后得到新的最终采样颜色,然后根据累积采样次数而来的权重和之前的采样历史结果加权更新。
参考实现
http://www.zentient.com/site/experiments/blox.html 这是我最早参考的demo, 场景中有64个box, 效果还不错。
http://madebyevan.com/webgl-path-tracing/
https://enkimute.github.io/webgl2PathTracing.js/
在着色器中使用加速结构
没有加速结构,光线追踪的渲染只能做一些极小的demo,根本没法做实际应用。根据一些了解,GPU的数据访问方式使用grid是最优的,也是普遍最快的,但是gird很难通用。想要gird发挥出最优的情况,一方面要手工调整和尝试grid的resolution等参数,另一方面要求场景的数据分布足够均匀,不能出现典型的体育馆中茶壶的情况。如果使用自适应的grid,实现难度非常大,而且能否很好的利用硬件的buff也不确定了。于是最后还是使用BVH。
之前在其他的地方做过sah策略的bvh。但我认为着色器这种环境下,还是强制平衡的tree比较安全,sah的树我看过,实际场景下平衡性不是太非常好。其实到最后我两种tree都实现了,sah似乎还真的没有平衡的效率高,这比较奇怪。
遇到的挑战
path trace的实现并不是很难的事情,最大的挑战来自:
1 使用webgl,特性少, 着色器无法调试。 webgl glsl不支持递归,webgl1甚至只有for循环,for循环还只能使用固定的step, 不然无法通过编译。除了向屏幕输出颜色,没有任何debug和调试的手段。
2 在着色器中实现主要trace逻辑,包括加速结构。因为前者的原因,trace逻辑稍有不慎则直接死循环,直接造成浏览器甚至显卡驱动崩溃。事实上,我用了数天时间,浏览器崩溃了无数次,才调试通了包含加速结构的raytrace核心逻辑。在看到正确结果出现的那一刻,无法想象自己完成了什么样的壮举。整个事情的难度仿佛是在瓶子里造船,非常硬核。
3 数据准备难度大,着色器中访问场景数据,加速结构,只能通过纹理。所以我就只能强行做数据纹理,在shader里计算什么情况要换行读数据,非常硬核。
事实上,当一年后我回头看这个项目,依然对自己的成果感到惊讶。
first triangle:


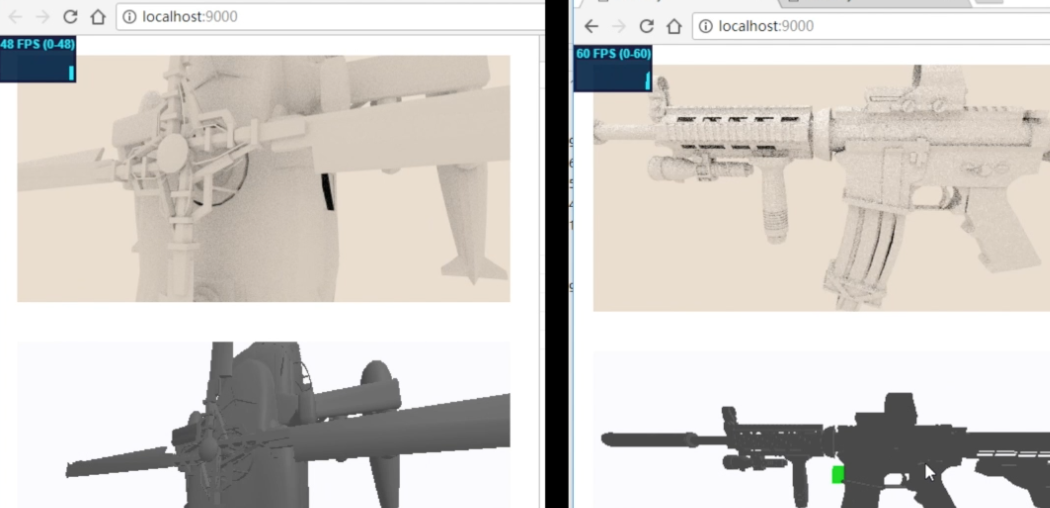
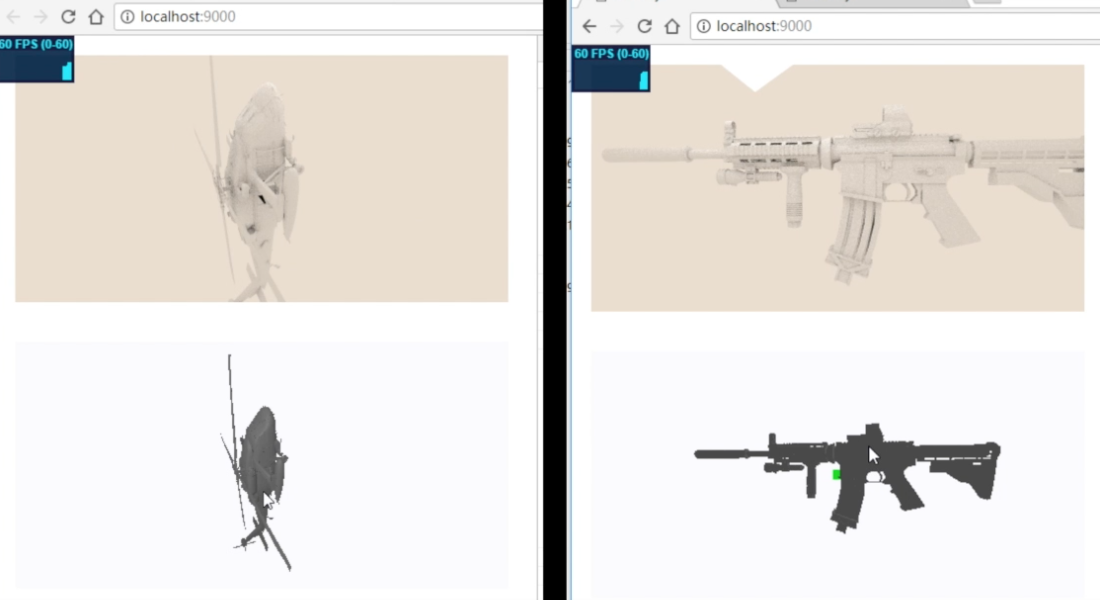
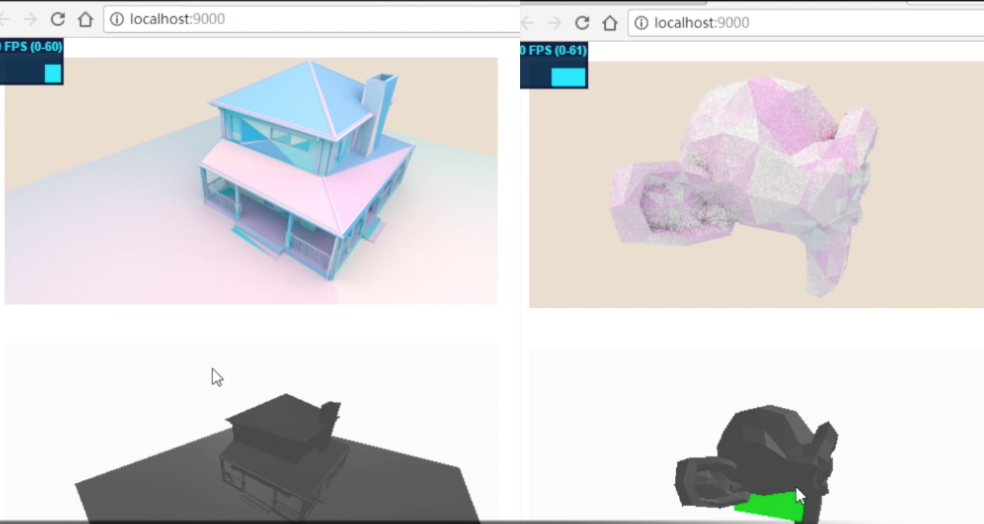
bvh深度复杂度可视化:

这几个模型面片数还是有的,机器是GTX1080,所以看起来没什么压力。